MLOps de niveau production pour vos modèles NLP
Le défi ? Plus de 87% des modèles ML ne parviennent jamais à la production. Notre solution : un pipeline MLOps automatisé et robuste qui garantit un déploiement fiable de vos modèles d'IA en moins de deux semaines.
Luminaire Conseil vous équipe d'une architecture MLOps visualisée, conçue pour l'excellence opérationnelle et la performance continue de vos assistants IA.
Demander une consultation MLOps gratuite
Support multi-modèles et architectures
Que vous travailliez avec les dernières innovations ou des architectures spécifiques, nous maîtrisons la diversité des environnements de modèles.
Modèles Génératifs (LLM)
Nous assurons le déploiement et l'optimisation des modèles de langage de grande taille comme GPT, Claude, Llama et Mistral, pour des applications conversationnelles et de génération de contenu avancées.
- Optimisation des coûts d'inférence
- Scalabilité horizontale et verticale
Modèles NLU Classiques
Expertise dans l'intégration et le déploiement de modèles de compréhension du langage naturel tels que BERT, RoBERTa, et d'autres modèles de classification pour l'analyse sémantique et l'extraction d'entités.
- Fine-tuning pour des domaines spécifiques
- Déploiement optimisé pour la latence
Architectures RAG (Retrieval Augmented Generation)
Nous construisons des solutions RAG robustes, intégrant des bases de données vectorielles, des modèles d'embeddings et des stratégies de récupération avancées pour une génération de réponses contextualisée et précise.
- Optimisation des performances de recherche
- Gestion intelligente du chunking
Modèles Custom & Hybrides
Au-delà des architectures standards, nous vous accompagnons dans le fine-tuning de modèles sur vos données propriétaires, l'implémentation de méthodes d'ensemble et le stacking de modèles pour des cas d'usage uniques.
- Adaptation précise à vos besoins métier
- Solutions hybrides pour performance optimale
Déploiement Edge
Pour les scénarios exigeant une latence minimale et une autonomie hors ligne, nous architecturons des solutions de déploiement de modèles directement sur des périphériques edge, garantissant des temps de réponse instantanés.
- Inférénce locale rapide
- Sécurité des données accrue

Le pipeline MLOps automatisé de Luminaire Conseil
Minimisez le risque et maximisez la vélocité avec notre pipeline MLOps de bout en bout, conçu pour la robustesse et l'efficacité.
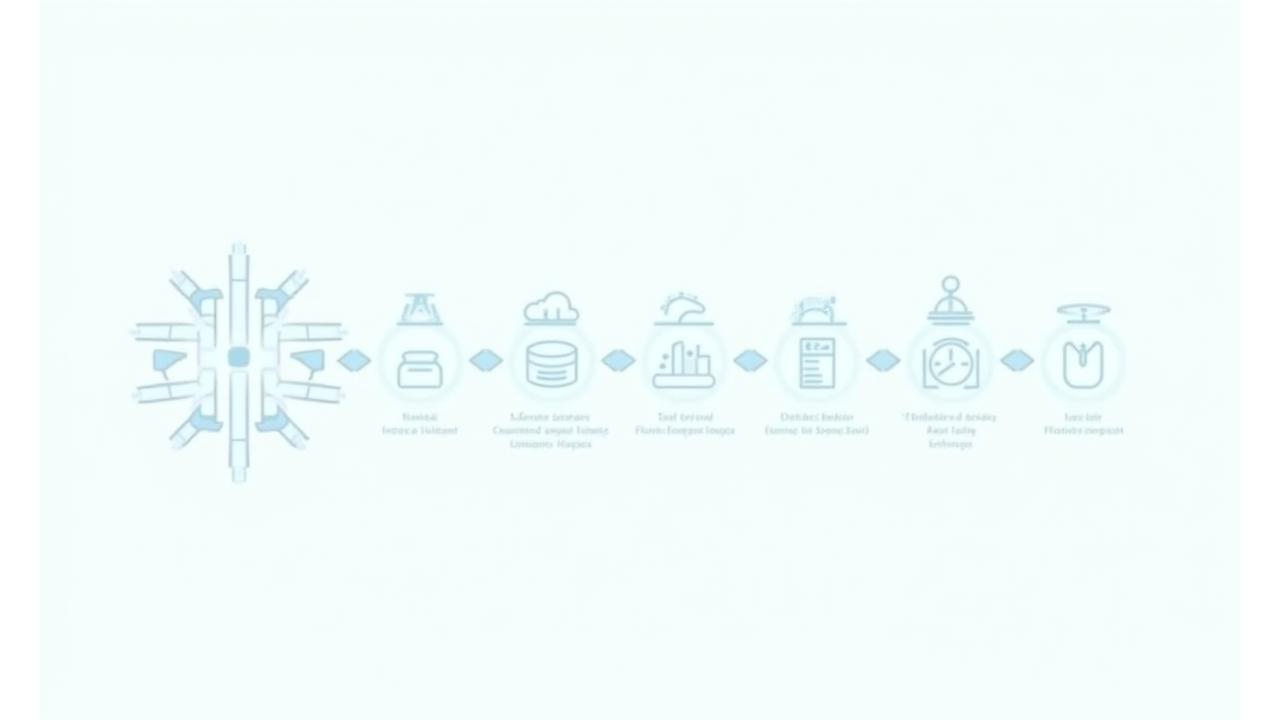
-
Ingestion & Prétraitement automatisés
Collecte et préparation des données sans effort, avec des processus et des outils qui garantissent la qualité et la cohérence.
-
Entraînement intelligent & Optimisation
Entraînez vos modèles avec des algorithmes d'optimisation des hyperparamètres, garantissant les meilleures performances possibles.
-
Validation & Tests de régression
Des tests automatiques garantissent que chaque nouvelle version du modèle maintient ou améliore les performances attendues, sans introduire de régressions.
-
Déploiement Blue-Green sans interruption
Mettez à jour vos modèles en production sans aucun temps d'arrêt, grâce à des stratégies de déploiement éprouvées.
-
Monitoring continu & Détection de dérive
Surveillance proactive pour détecter la dégradation des performances du modèle ou la dérive des données, permettant des interventions rapides.
-
Rollback automatique en cas d'anomalie
Des mécanismes de sécurité intégrés assurent un retour automatique à la version stable précédente en cas de détection d'une anomalie critique.
Architecture RAG optimisée pour des assistants contextualisés
Maximisez la pertinence et la précision des réponses de vos assistants IA avec nos architectures RAG sur mesure.
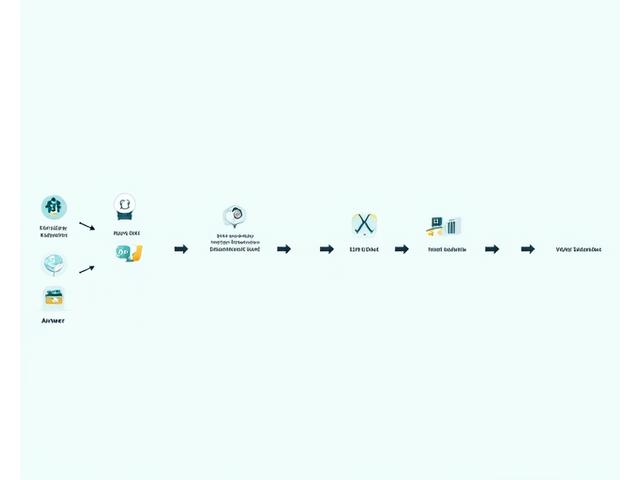
-
Bases de données vectorielles de pointe
Intégration et optimisation avec les leaders du marché comme Pinecone, Weaviate et Qdrant pour une récupération sémantique rapide et efficace.
-
Modèles d'embeddings optimisés par domaine
Sélection et fine-tuning de modèles d'embeddings pour garantir la meilleure représentation contextuelle de vos données métier.
-
Stratégies de "chunking" pour documents complexes
Des approches intelligentes pour diviser vos documents en portions optimales, maximisant la pertinence du contexte récupéré.
-
Recherche Hybride (sémantique + mot-clé)
Combinaison de la puissance de la recherche sémantique et par mot-clé pour une récupération exhaustive et précise.
-
Re-ranking et filtrage contextuel intelligent
Des mécanismes post-récupération pour affiner les résultats et présenter uniquement le contexte le plus pertinent au LLM.
-
Caching intelligent des embeddings
Minimisez la latence et les coûts en mettant en cache les embeddings fréquemment consultés, accélérant ainsi les requêtes.
Frameworks d'évaluation continue pour la qualité de l'IA
Assurez la fiabilité et la performance de vos modèles en production grâce à nos méthodologies d'évaluation rigoureuses et continues.
-
Métriques qualité standards et avancées
Utilisation de métriques telles que BLEU, ROUGE, BERTScore, ainsi que des métriques personnalisées pour évaluer la qualité et la pertinence des sorties de vos modèles.
-
Évaluation humaine et annotation workflows
Mise en place de processus rigoureux d'évaluation par des experts humains, complétée par des workflows d'annotation efficaces pour un feedback qualitatif continu.
-
A/B testing automatisé des variants de modèles
Déployer et comparer différentes versions de modèles en production pour identifier celle qui offre les meilleures performances en conditions réelles.
-
Monitoring du "bias" et de l'équité (fairness)
Des outils et des processus pour détecter et atténuer les biais potentiels dans les prédictions et les sorties des modèles, assurant une IA équitable.
-
Red Teaming pour sécurité et robustesse
Des tests de vulnérabilité et des attaques simulées pour identifier les failles de sécurité, les comportements imprévus ou toxiques de vos modèles.
-
Benchmarks industriels et comparaisons
Alignez vos performances sur les meilleures pratiques de l'industrie grâce à des benchmarks réguliers et des comparaisons avec des modèles de référence.

Infrastructure scalable et optimisée pour l'IA
Bénéficiez d'une infrastructure robuste, flexible et rentable, conçue pour supporter les exigences les plus complexes de vos modèles d'IA.

-
Clusters GPU avec auto-scaling intelligent
Des ressources de calcul GPU qui s'adaptent automatiquement à la demande, optimisant les performances et les coûts.
-
Model serving avec load balancing avancé
Des serveurs de modèles performants avec équilibrage de charge pour gérer des millions de requêtes tout en maintenant une faible latence.
-
Caching multi-niveau pour latence optimale
Mettez en place des stratégies de cache intelligentes à différents niveaux pour réduire drastiquement les temps de réponse.
-
Optimisation des coûts avec "spot instances"
Réduisez significativement vos dépenses cloud en exploitant des instances à la demande pour les charges de travail tolérantes aux interruptions.
-
Multi-cloud deployment pour résilience accrue
Bénéficiez d'une plus grande redondance et résilience en déployant vos modèles sur plusieurs fournisseurs de cloud, minimisant les risques de panne unique.
-
Inférence Edge pour les cas critiques
Quand chaque milliseconde compte, déployez vos modèles directement sur des appareils en périphérie de réseau pour une inférence quasi instantanée.
Fine-tuning et adaptation de modèles sur vos données
Transformez des modèles génériques en experts de votre domaine avec nos services de fine-tuning avancés.
-
Adaptation de domaine sur vos données métier
Formez des modèles sur vos corpus uniques pour qu'ils comprennent les subtilités, le jargon et les conventions spécifiques à votre industrie.
-
Parameter-Efficient Fine-Tuning (PEFT) : LoRA, AdaLoRA
Des techniques de fine-tuning efficaces qui permettent d'adapter les modèles LLM avec des ressources moindres et des résultats optimaux.
-
Instruction tuning pour comportements spécifiques
Guidez le comportement de votre modèle pour qu'il suive des instructions complexes ou produise des sorties structurées et ciblées.
-
RLHF (Reinforcement Learning from Human Feedback) pour l'alignement
Alignez le modèle sur les préférences et les valeurs humaines pour des interactions plus naturelles et éthiques.
-
Distillation de modèles pour la compacité
Réduisez la taille et la complexité des modèles volumineux tout en conservant une grande partie de leurs performances, idéal pour le edge ou les contraintes de ressources.
-
Évaluation avant/après avec métriques métier
Mesurez précisément l'impact du fine-tuning sur des métriques directement liées à vos objectifs métier et vérifiez le ROI.

Consultation MLOps personnalisée
Prêt à transformer votre approche du déploiement IA ? Nos experts sont là pour vous guider, de l'audit initial à l'implémentation complète.
-
Audit approfondi de votre stack ML actuel
Nous réalisons une analyse complète de vos infrastructures, de vos outils et de vos processus pour identifier les points forts et les axes d'amélioration.
-
Recommandations d'architecture optimale
Nous concevons une architecture MLOps sur mesure, alignée sur vos objectifs métier et vos contraintes techniques.
-
POC sur votre cas d'usage prioritaire
Démarrez rapidement avec un "Proof of Concept" concret sur un de vos cas d'usage clés, démontrant la valeur ajoutée de notre approche.
-
Formation de vos équipes aux meilleures pratiques
Nous transmettons notre expertise à vos équipes pour qu'elles puissent maintenir et faire évoluer vos pipelines MLOps en toute autonomie.
-
Feuille de route de migration progressive
Nous élaborons un plan détaillé pour une transition fluide et sécurisée vers une infrastructure MLOps de pointe.